关于Jupyter中数据分析工具Pandas详细介绍 |
您所在的位置:网站首页 › sqlalchemy pandas 写入 › 关于Jupyter中数据分析工具Pandas详细介绍 |
关于Jupyter中数据分析工具Pandas详细介绍
|
数据分析工具Pandas介绍
Panda数据结构分析Pandas索引操作及高级索引Series的索引操作DataFrame
算术运算与数据对齐数据排序按索引进行排序按值进行排序
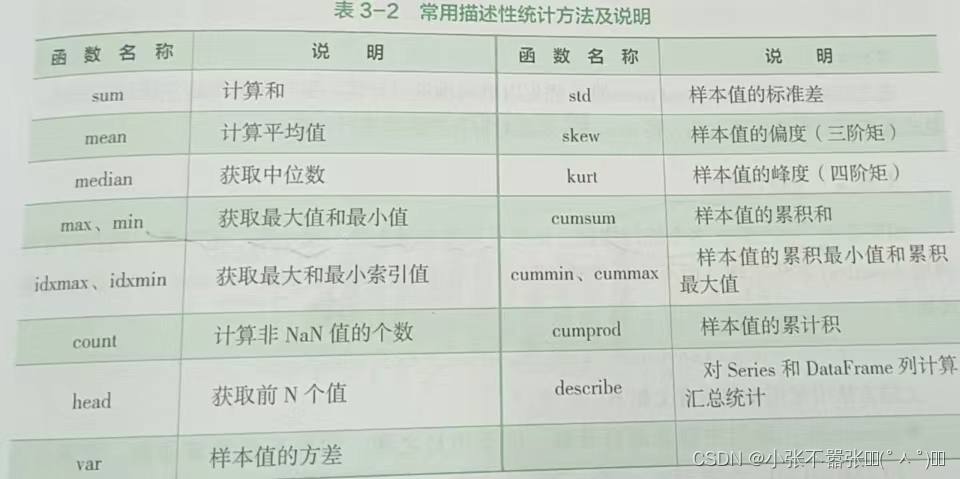
统计计算与描述层次化索引读写数据操作
Panda数据结构分析
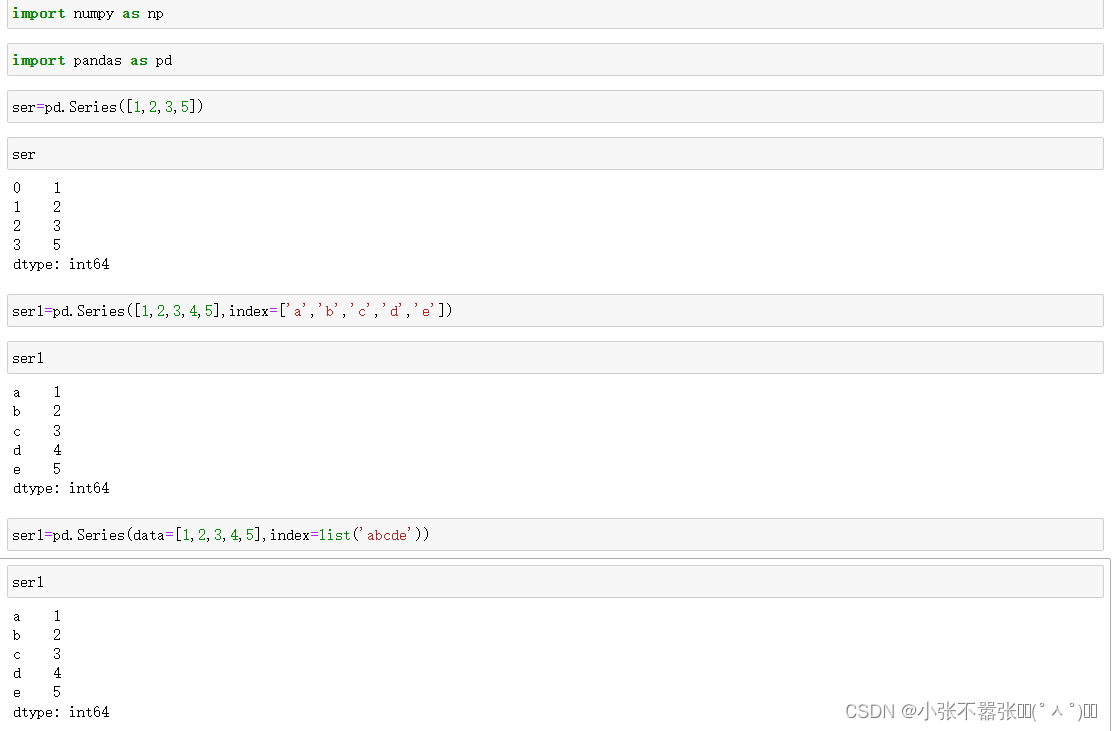
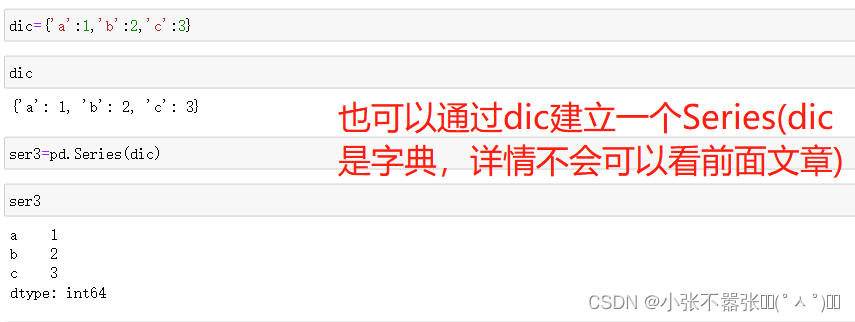
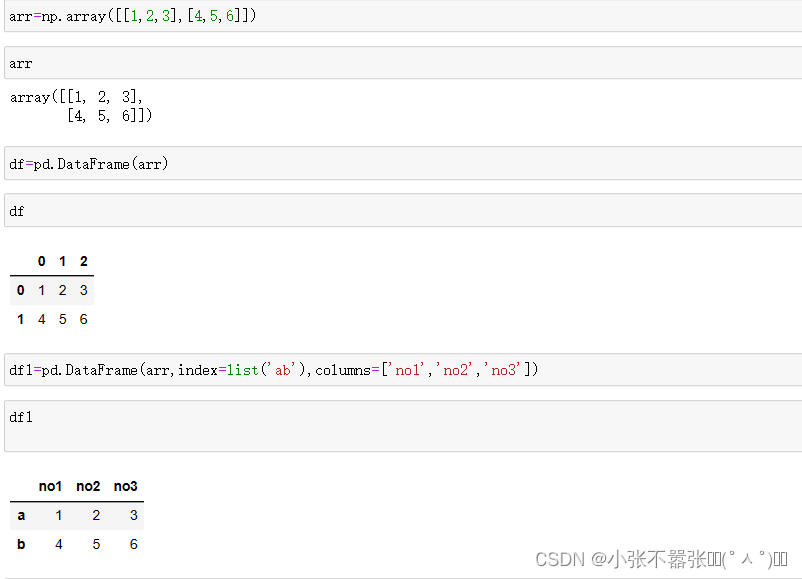
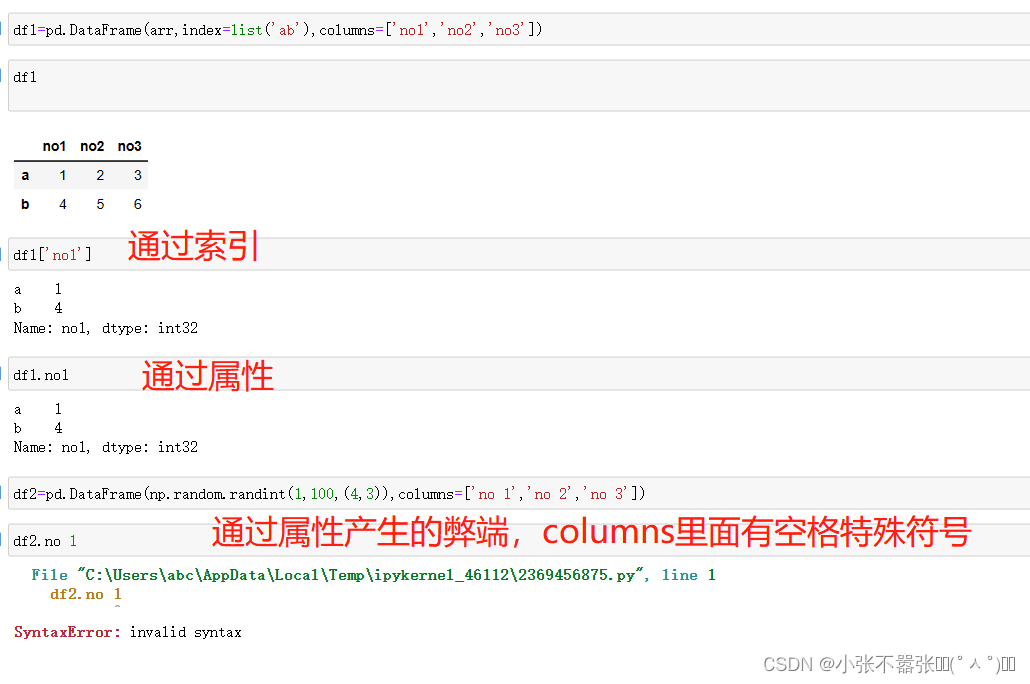
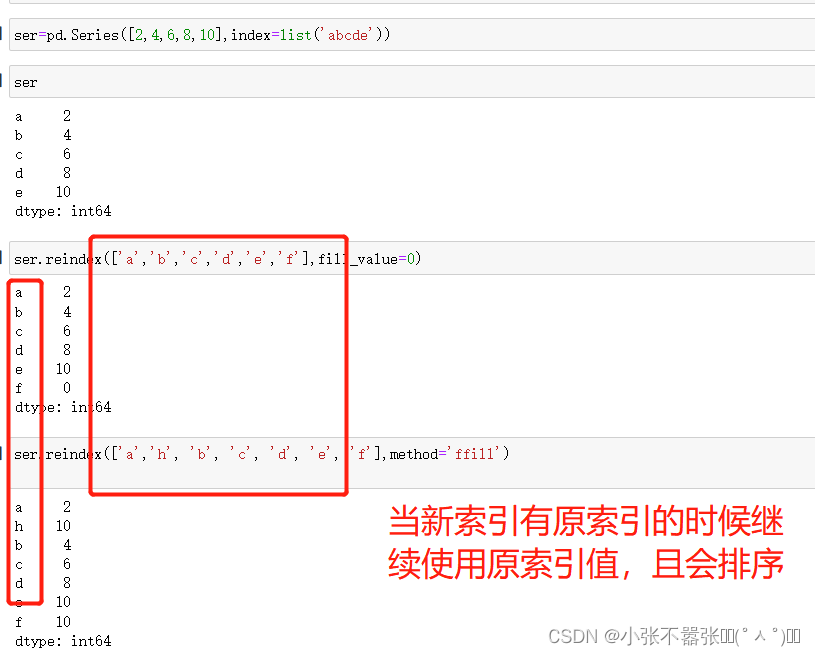
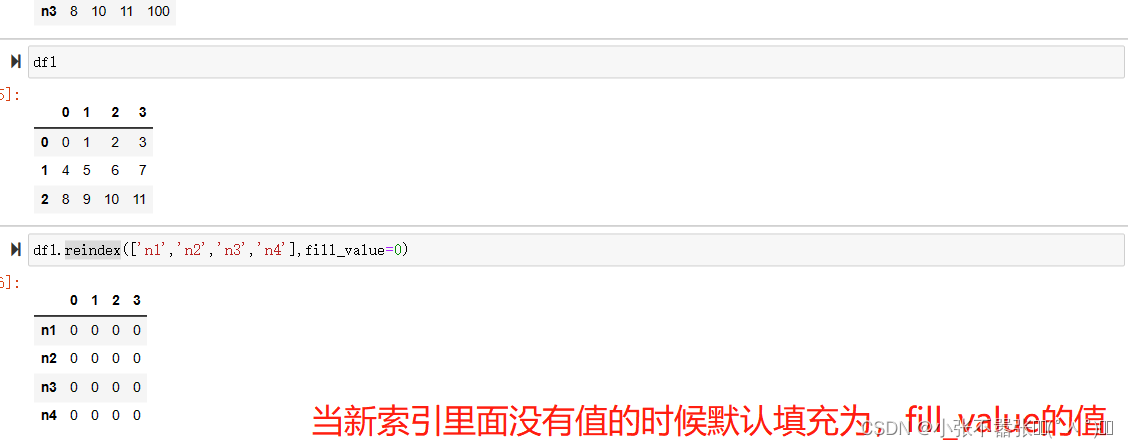
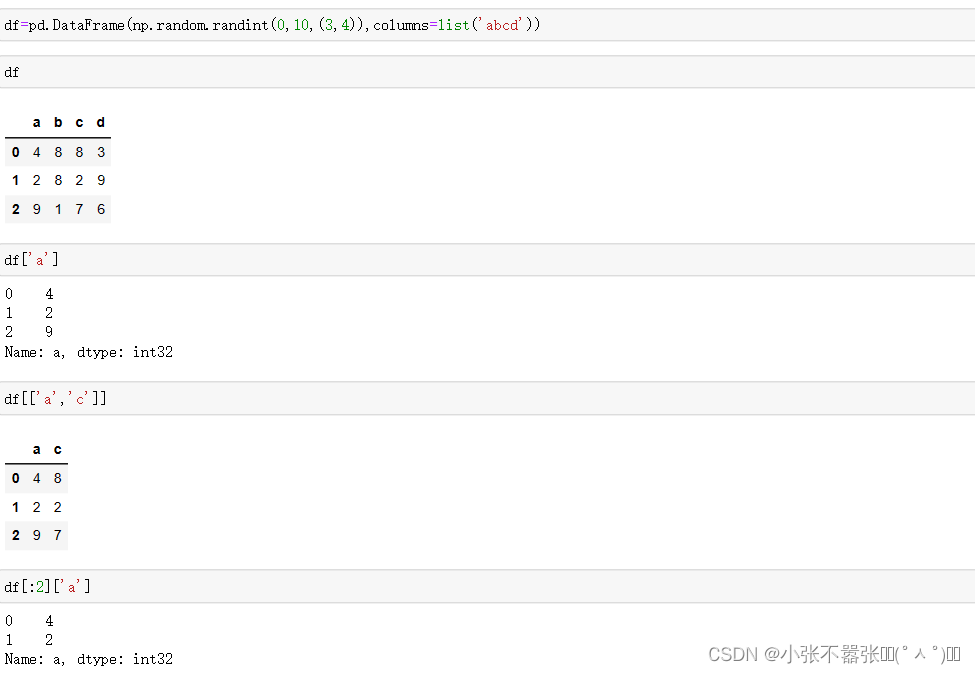
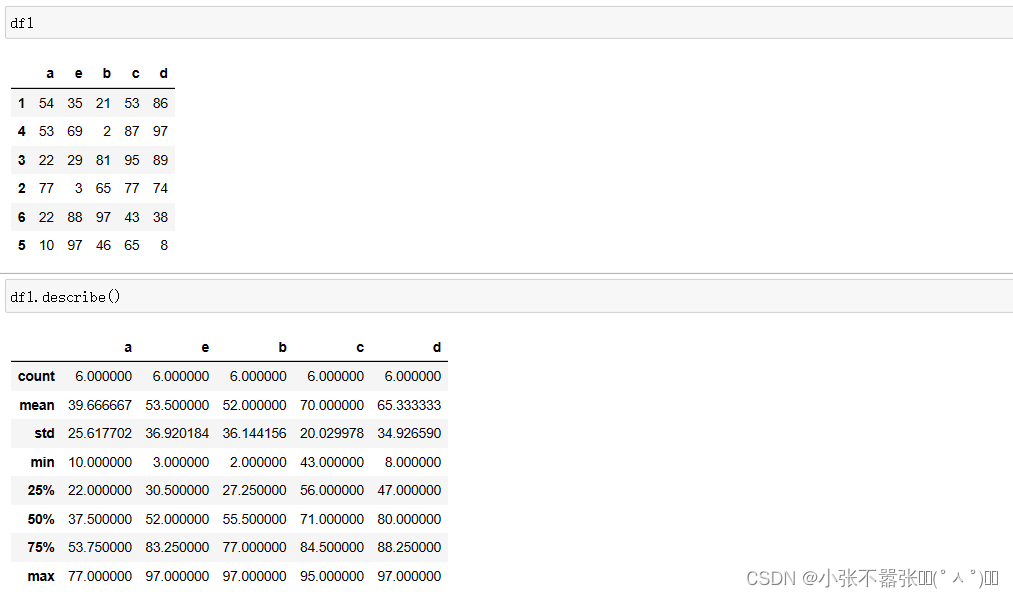
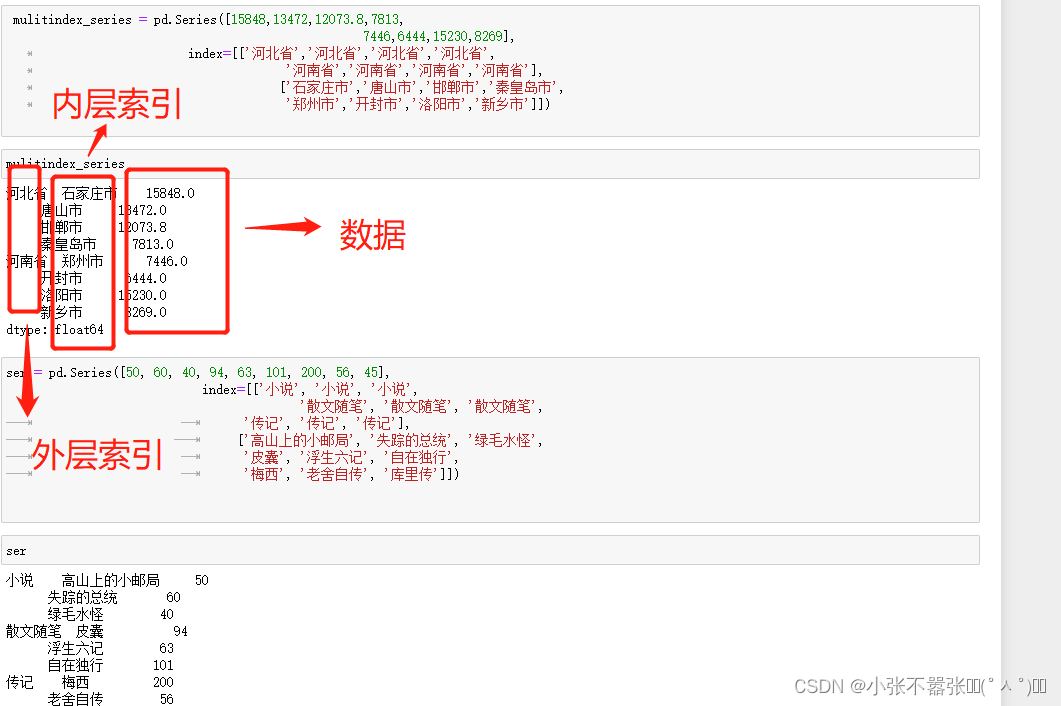
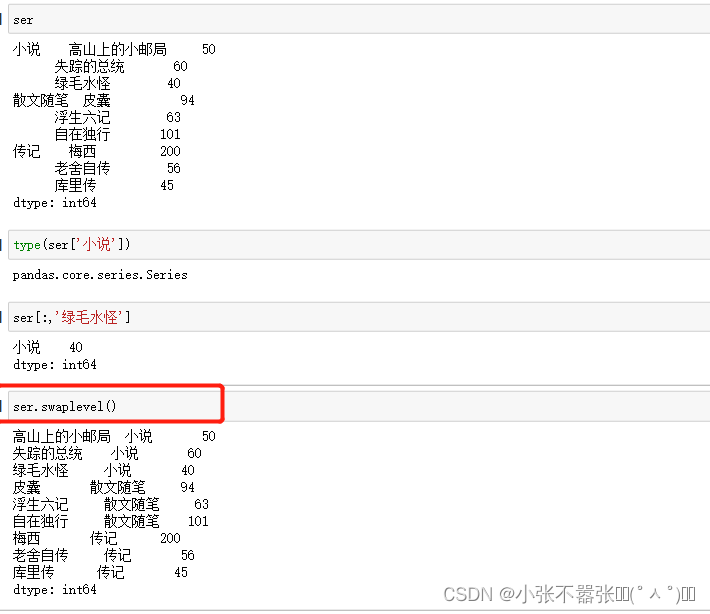
一般来说,我们Panda中有两个数据结构,一个是Series,另一个是DataFrame 一、Series Series类似于一个一维的数组对象能够保存任何数据类型,其中Series索引再左边数据在右边 Pandas.Series(data=None,index=none,dype=none,copy=none) #data作为传输的数据可以是列表,数组 #index是索引是唯一的,且与数据的长度是一致的,默认是0-n #dtype是数据类型,copy是,是否复制数据创建Series 二、DataFrame DataFram类似于一个二维数组或者表格,每列可以是不同的数据类型与Series结构类似,结构如下所示 pd.DataFram(data=none,index=none,columns=none,dytpe=none,copy=none) #index为行标签,如果没有传入默认是0-n #columns为列标签,如果没有传入默认也是0-n #其余属性和Series一样Series为了更加方便的操作Series对象为此提供了两个属性,index和value,通过这两个数据可以获取到Series的索引和数据 创建DataFram DataFrame为了便利的获取到数据,有两种方法可以 一:可以通过索引的方法进行或者 二:可以通过属性的方式来获取(有个弊端,当属性里面有空格或者特殊符号的时候会报错) 重置索引 reindex()方法的作用是对原索引和新索引进行匹配,也就是说,新索引含有原索引的数据,而原索引数据按照新索引排序,如果新索引没有原数据程序不会报错,会自动填充nan或者通过fill_values()进行填充 DataFrame.reindex(labels=none,index=none,columns=none, axis=none,method=none,fill_value=nan,limit=none) #index用作索引的新序列 #method插值的填充方式 #fill_引入缺失值使用的替代值 #limit向前或者向后填充时最大填充量
|

 索引操作
索引操作 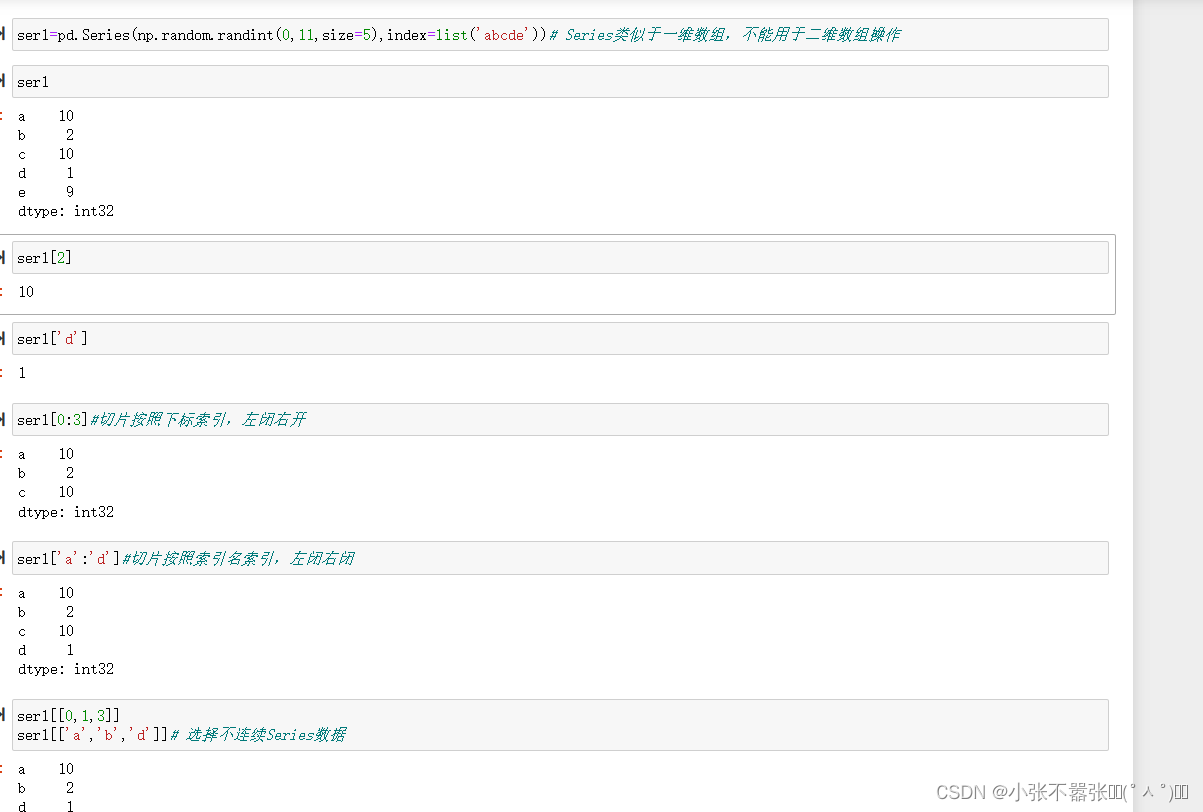
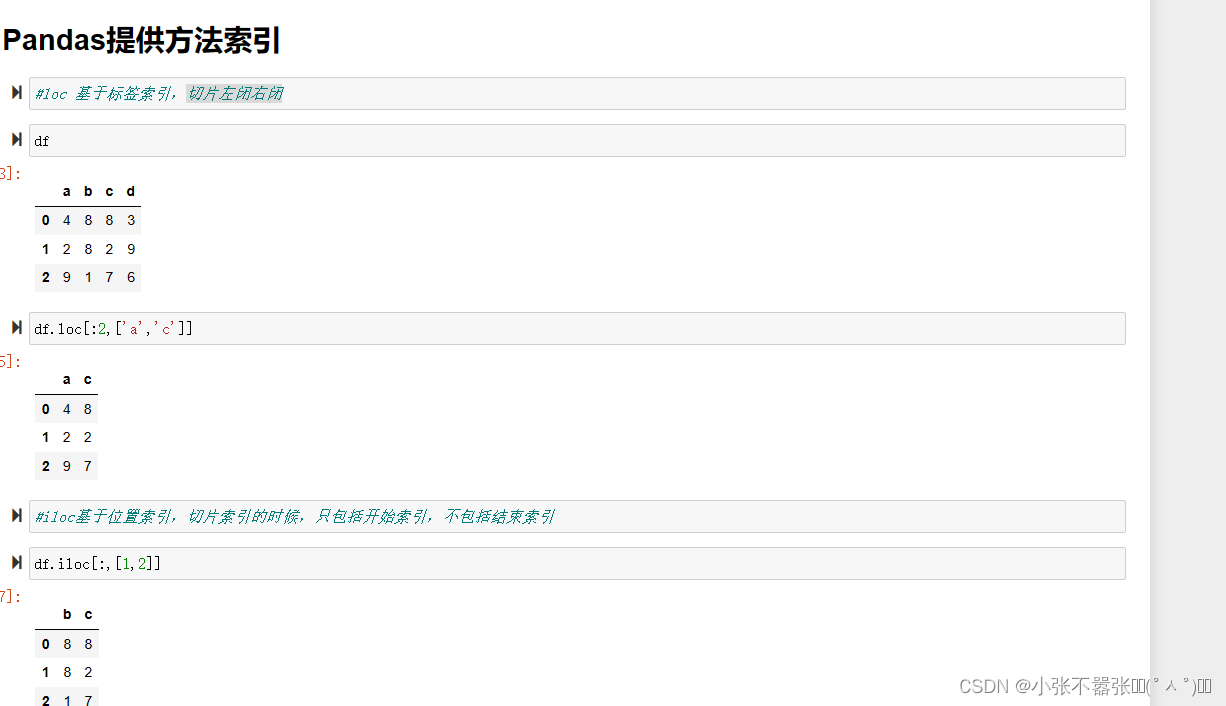
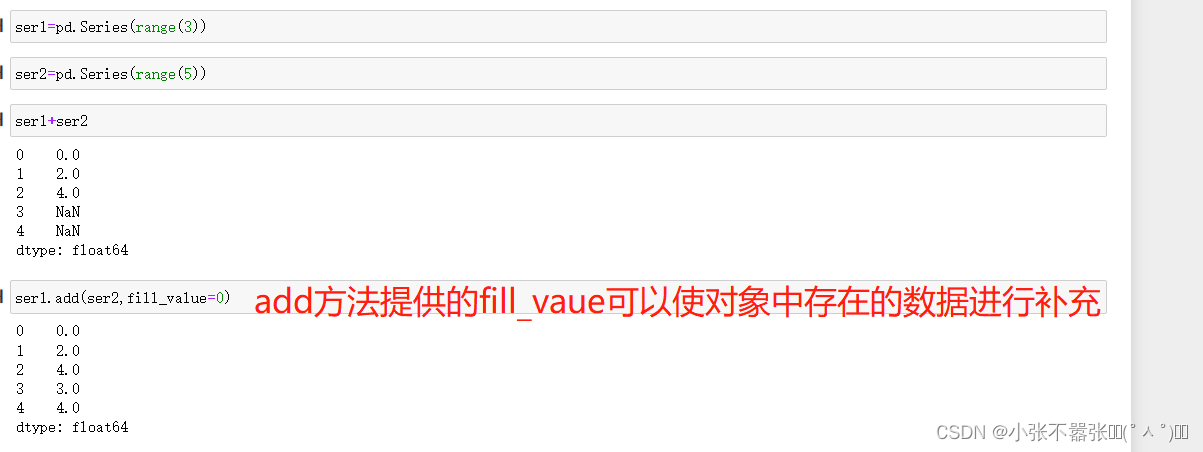
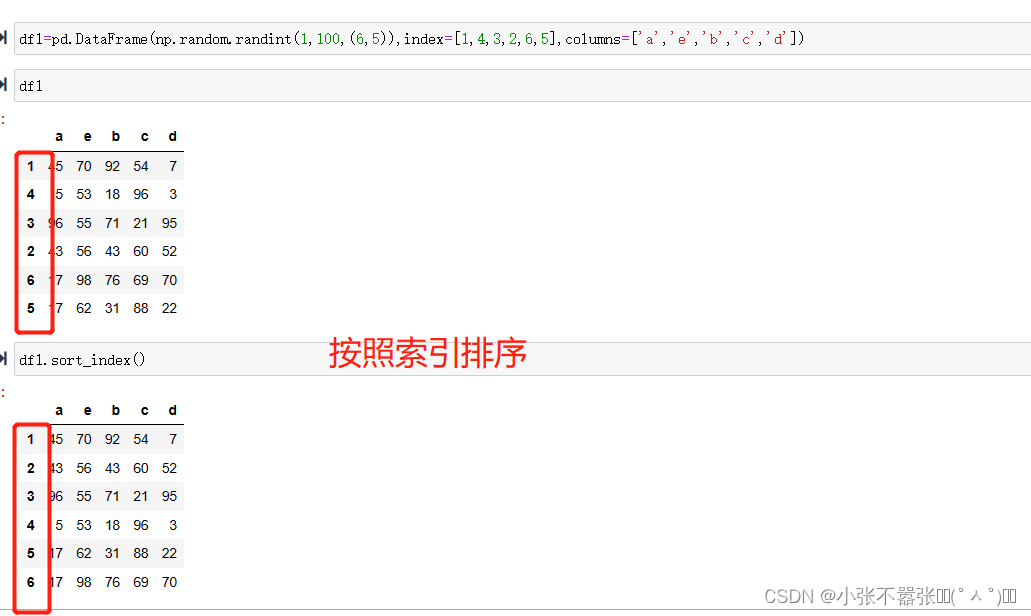
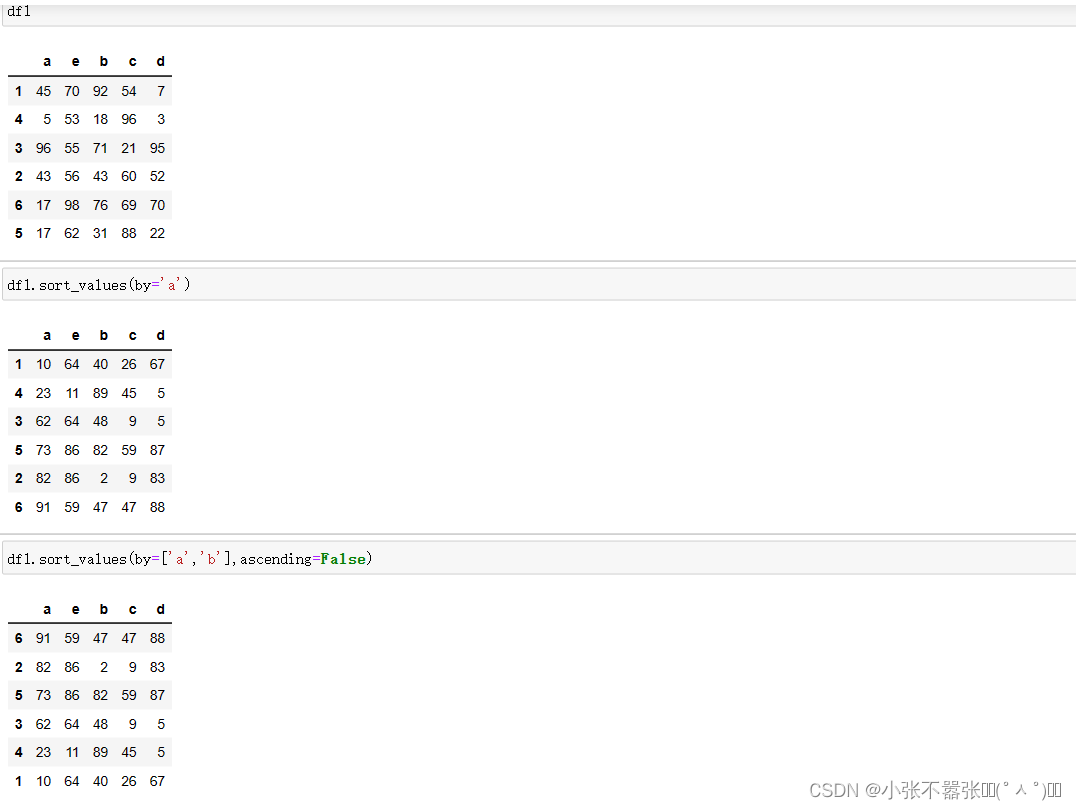


【本文地址】
今日新闻 |
推荐新闻 |